AI models keep scaling while fresh silicon (GPUs, TPUs, NPUs, you name it) hits the market every year. That widening hardware zoo leaves a gap: high-level Python builds ever-larger graphs, but each graph still needs hand-tuned kernels to run fast on the latest chip. Yesterday the fix was to write CUDA or OpenCL by hand or wait for cuDNN-style libraries to catch up. Today a different approach is taking over: modern compilers slide an intermediate representation (IR) between model and metal, so one translation step, not bespoke kernels, unlocks every device.
In 2015 SPIR-V gave GPUs a vendor-neutral bytecode. Three years later TVM showed that an auto-tuner could outpace handwritten CUDA on day one. By 2019 MLIR turned compiler plumbing into reusable Lego blocks. These three breakthroughs (portability, auto-optimization, and modularity) now sit behind the compile button in most ML stacks.
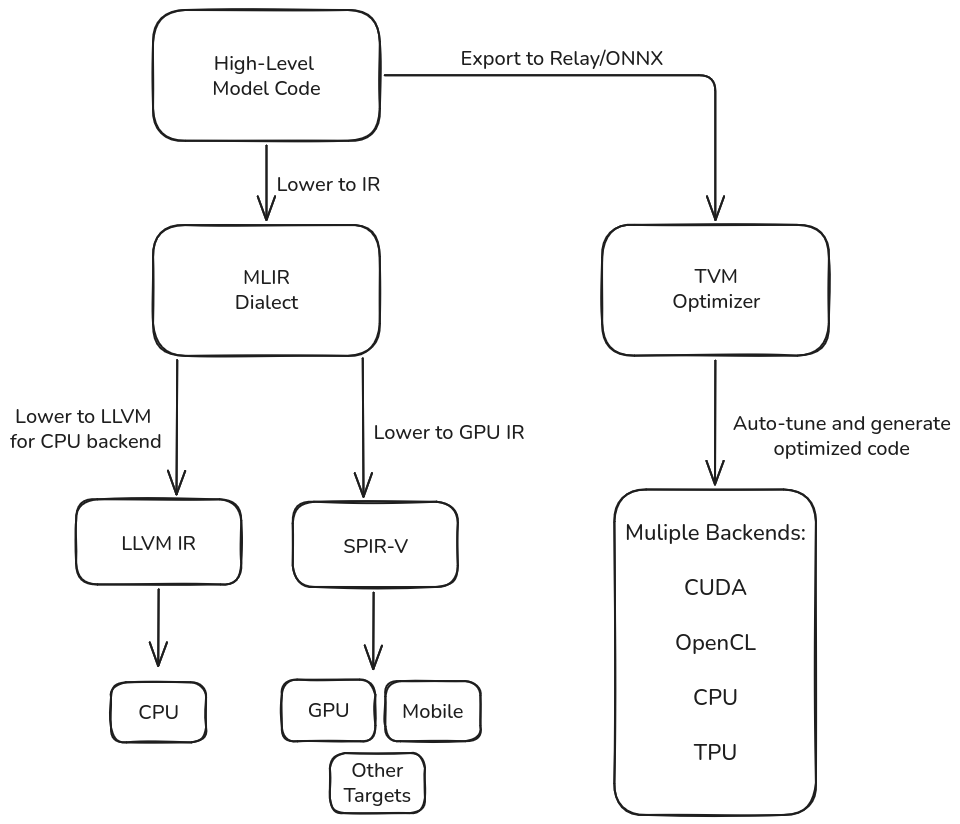
MLIR — the modular backbone
MLIR splits a compiler into dialects that capture successive abstraction layers: tensor graphs, affine loops, hardware intrinsics. A pass added to one dialect (say, loop fusion) automatically benefits every project that reuses that dialect, from IREE to Torch-MLIR. Lowering to LLVM, SPIR-V or bespoke silicon happens late, after the heavy lifting is shared.
TVM — the turnkey optimizer
Feed TVM a saved PyTorch, TensorFlow or ONNX model; it rewrites the graph, lowers to tensor-level IR and brute-forces kernel schedules until the fastest variant wins. That auto-search delivered ~30 % extra throughput on Apple M1 the week the chip shipped—no manual kernels, no vendor lock-ins. TVM then emits tuned binaries for CPUs, GPUs and NPUs in one sweep.
SPIR-V — the portable runway
SPIR-V isn’t a compiler; it’s the last IR hop. Emit it and the same binary runs on NVIDIA, AMD, Intel iGPUs or a mobile Mali as long as a conforming driver is present. By pushing portability down to the driver layer, SPIR-V removes the final hard dependency on CUDA-style ecosystems.
How the pieces fit
MLIR supplies reusable stages, TVM adds production-grade autotune on top, and SPIR-V is the landing zone for any GPU. In most toolchains they cooperate rather than compete: MLIR dialects feed TVM optimizers, which then lower to SPIR-V for execution on whatever silicon is available.
Impact
- PyTorch 2.0.
torch.compile()now routes graphs through MLIR-style passes before handing them to back ends such as Triton or OpenXLA, squeezing double-digit speed-ups on Gaudi-3 and CUDA alike. - JAX & TensorFlow. Both lean on OpenXLA, whose StableHLO dialect is implemented in MLIR; JIT-compilation sends those graphs through the same optimization chute before they hit TPUs, GPUs or CPUs.
- Hugging Face Optimum. One CLI switch compiles a transformer with TVM, generates SPIR-V, and serves it via WebGPU—bringing near-desktop throughput to browsers and Android devices without code changes.
- Cost & reach. Unified IR pipelines mean fewer bespoke kernels, quicker hardware bring-up, and lower cloud invoices: optimize once, deploy everywhere. As accelerators proliferate, the compiler layer—not bigger models—will decide who ships state-of-the-art inference first.
Conclusion
Hand-tuned kernels aren’t gone yet, but the momentum is clear. With IR-centric compilers bridging Python and metal, the next breakthrough may be the toolchain that lets tomorrow’s model run anywhere, fast.